Speech Overview
You can use the Speech service to convert media files to readable text that's stored in JSON and SRT format.
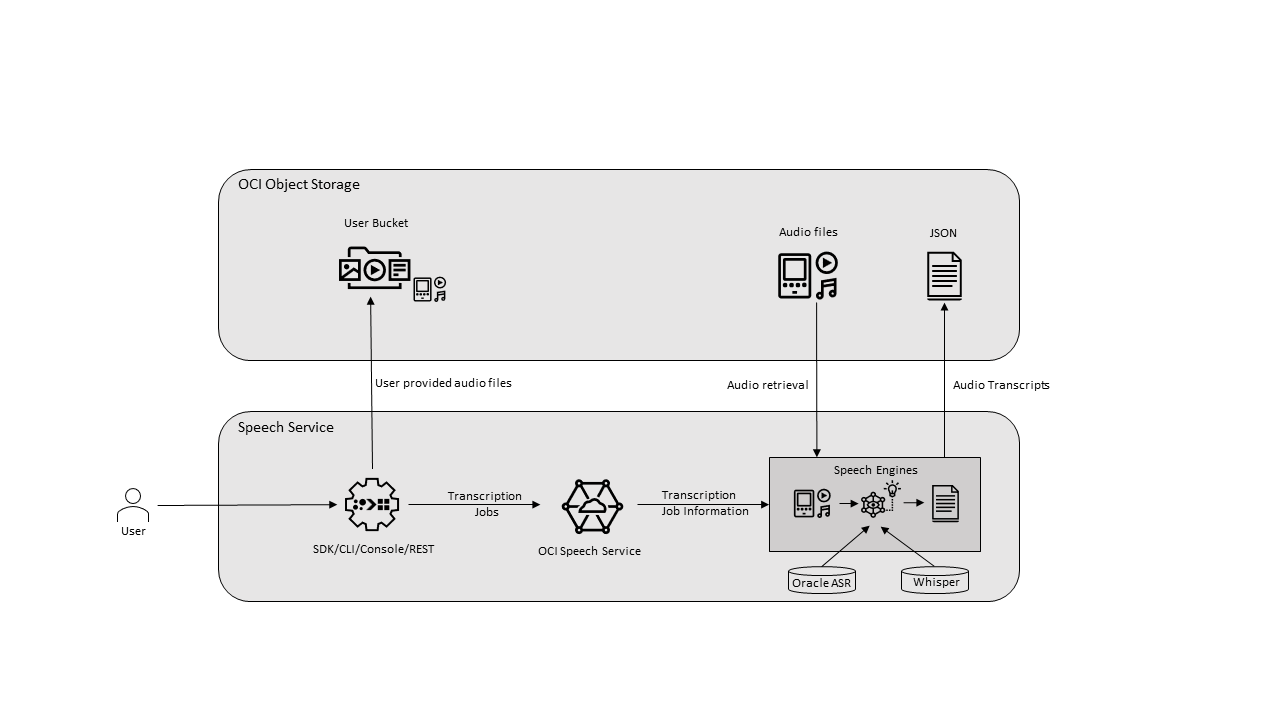
Speech harnesses the power of spoken language enabling you to easily convert media files containing human speech into highly exact text transcriptions. The service is an Oracle Cloud Infrastructure (OCI) native application that you can access using the Console, REST API, CLI, and SDK. In addition, you can use the Speech service in a Data Science notebook session.
Speech uses automatic speech recognition (ASR) technology to provide a grammatically correct transcription. Speech handles low-fidelity media recordings and transcribes challenging recordings such as meetings or call centers calls. Using Speech, you can turn files stored in Object Storage or a data asset into exact, normalized, timestamped, and profanity-filtered text. This functionality is only available with the Speech. For example, you could index the output of speech (a text file) using Data Lake. Without the downstream services, this capability doesn't exist in Speech.
The Speech models are robust to acoustic environments and recording channels that ensure that this is a good quality transcription service.
Multiple Media Format Support per Language
These media formats are supported for all supported languages in the Speech service:
-
AAC -
AC3 -
AMR -
AU -
FLAC -
M4A -
MKV -
MP3 -
MP4 -
OGA -
OGG -
OPUS -
WAV -
WEBM
| Language | Language Code | Sample Rate |
|---|---|---|
| English—United States |
en-US
|
>= 8 khz |
| Spanish—Spain |
es-ES
|
>= 8 khz |
| Portuguese—Brazil |
pt-BR
|
>= 8 khz |
| English—Great Britain |
en-GB
|
>= 16 khz |
| English—Australia |
en-AU
|
>= 16 khz |
| English—India |
en-IN
|
>= 16 khz |
| Hindi—India |
hi-IN
|
>= 16 khz |
| French—French |
fr-FR
|
>= 16 khz |
| German—Germany |
de-DE
|
>= 16 khz |
| Italian—Italy |
it-IT
|
>= 16 khz |
For best results:
- Use a lossless format such as FLAC or WAV with PCM 16-bit encoding.
- Use a sample rate of 8, 000 Hz for low-fidelity media and 16,000 to 48, 000 Hz for high fidelity media.
You can use single-channel, 16-bit PCM WAV media files with an 8 kHz or 16 kHz sample rate. We recommend Audacity (GUI) or FFmpeg (command line) for media transcoding. A maximum media file length of four hours and up to 2 GB is supported.
Speech is susceptible to the quality of the input media files. Different accents, background noises, switching from one language to another, using fusion languages, or multiple speakers at the same time impact the quality of the transcription.
Speech Provides These Capabilities
-
Accurate transcriptions—Produces an accurate and easy to use JSON and SubRip Subtitle (SRT) files written directly to the Object Storage bucket you choose. You can take advantage of the transcription and integrate it directly with applications, and use it for subtitles or content search and analysis.
- Whisper model—Multilingual data is collected from the web and supports file based voice to text transcription for 50+ languages.
-
Time stamped JSON—The transcription provides a timestamp for each token (word). You can use the timestamp to search and find the text you're looking for within the media file then quickly jump to that location.
-
Multilingual—Produces accurate transcriptions in English, English-Great Britain, English-Australia, English-India, Spanish, Portuguese, French, Italian, German, and Hindi.
-
Asynchronous API—Straightforward asynchronous APIs with transcription task batching. The APIs enable canceling jobs that aren't yet processed saving time and money.
-
Text normalizations—Provides text normalizations for numbers, addresses, currencies, and so on. With text normalizations, you get a higher-quality transcription from artificial intelligence that's easier to read and understand.
-
Profanity filtering—Allows you to remove, mask, or tag words that are offensive from the transcription.
-
Confidence score per word and transcription—Produces word and transcription confidence scores on the generated JSON file. You can use the confidence scores to quickly identify words that require attention.
-
Closed captions—Provides you with an SRT file as an extra output format. Use the SRT to add closed captions to video files.
-
Punctuation—Long text requires punctuation so Speech punctuates the transcribe content automatically.
-
Telephoney ready—Files can be 8 kHz or 16 kHz and each are automatically detected so that the correct model is applied. With this capability, you can transcribe telephone recordings.
-
Speaker diarization—Associates transcription text with specific speakers using natural-language understanding scenarios, such as extracting a prescription from medical audio by identifying the service provider compared to the patient. Speaker diarization is a combination of speaker segmentation and speaker clustering. Speaker segmentation finds the speaker change points in an audio stream. Speaker clustering groups together speech segments based on speaker characteristics.
Key Concepts
These are the key Speech service concepts:
- Transcription Jobs
-
A job is a single asynchronous request from the Console or the Speech API. Each job is uniquely identified by an id, which you can use to retrieve job status and results.
A job in a tenant is processed in a strict first in first out manner. Each job can contain up to 100 tasks. If you submit a job that exceeds the maximum tasks, that job fails. Jobs are retained for 90 days.
- Live Transcribe
- Allows you to send an audio stream to the service and receive the results in text (JSON & SRT format) in real time.
- Tasks
-
A task is the result of a single file processed in a job. Jobs can have multiple tasks based on what's stored in your Object Storage bucket that you specify for a job.
- Models
-
Pretrained acoustic and language models, including Whisper models, power the job transcription process.
Authentication and Authorization
Each service in OCI integrates with IAM for authentication and authorization, for all interfaces (the Console, SDK or CLI, and REST API).
An administrator in your organization needs to set up groups , compartments , and policies that control which users can access which services, which resources, and the type of access. For example, the policies control who can create new users, create and manage the cloud network, launch instances, create buckets, download objects, and so on. For more information, see Getting Started with Policies.
- For details about writing Speech policies, see About Speech Policies.
- For details about writing policies for other services, see Policy Reference.
If you're a regular user (not an administrator) who needs to use the OCI resources that your company owns, contact your administrator to set up a user ID for you. The administrator can confirm which compartment or compartments you should be using.
Resource Identifiers
The Speech service supports jobs and tasks as OCI resources. Most types of resources have a unique, Oracle-assigned identifier called an Oracle Cloud ID (OCID). For information about the OCID format and other ways to identify your resources, see Resource Identifiers.
Regions and Availability Domains
Speech is available in all OCI commercial regions. See About Regions and Availability Domains for the list of available regions for OCI, along with associated locations, region identifiers, region keys, and availability domains.
Text to Speech is only available in the US West (Phoenix) commercial region.
Ways to Access
You can access Speech using the Console (a browser-based interface), the command line interface (CLI), or the REST API. Instructions for the Console, CLI, and API are included in topics throughout this guide.
To access the Console, you must use a supported browser. To go to the Console sign-in page, open the navigation menu at the top of this page and click Infrastructure Console. You are prompted to enter your cloud tenant, your user name, and your password.
For a list of available SDKs, see SDKs and the CLI. For general information about using the APIs, see REST API.
Service Limits
In each region that's enabled for your tenancy, these limits apply:
-
The maximum file size is 2 GB.
-
File duration is a maximum of 4 hours.
Text to Speech
Text to speech supports maximum 10000 characters per request.
Live Transcribe
Live transcribe supports maximum 10 concurrent sessions per tenancy. Limit can be raised by opening a service request with Oracle support. For more information, see Creating a Limit Increase Request.
Comparing Whisper and Oracle ASR Models
Compare Whisper model and Oracle ASR model for creating transcription jobs.
In addition to the native Oracle ASR speech model, Speech supports the Whisper model from OpenAI. Whisper is trained on a large corpus of multilingual data collected from the web, and it supports file-based voice-to-text transcription for over 50 languages. This model uses the same service end points and API and SDK interfaces as the Oracle ASR model to give you flexibility and compatibility. In addition, the Whisper model uses diarization to label individual speakers in the recording.
Use the following comparison of the Whisper and Oracle ASR models to select the correct model when creating a transcription job.
| Feature | Oracle ASR Model | Whisper Model in OCI Speech |
|---|---|---|
| Real time transcriptions | Supported | Supported |
| Large file size | Up to 2 GB | Up to 2 GB |
| Word level timestamp | Supported | Supported |
| File format | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM |
| Multilingual support | English, Spanish, French, German, Italian, Portuguese, and Hindi | Same as Oracle ASR model plus 50 other languages* |
| Diarization | Supported | Supported |