Pretrained Document AI Models
Vision provides pretrained document AI models that let you organize and extract text and structure from business documents.
The AnalyzeDocument and DocumentJob capabilities in Vision are moving to a new service, Document Understanding . The following features are impacted:
- Table detection
- Document classification
- Receipt key-value extraction
- Document OCR
Use Cases
Pretrained document AI models let you automate back-office operations, and process receipts more accurately.
- Intelligent search
- Enrich image-based files with metadata, including document type and key fields, for easier retrieval.
- Expense reporting
- Extract the required information from receipts to automate business workflows. For example, employee expense reporting, spending compliance, and reimbursement.
- Downstream Natural Language Processing (NLP)
- Extract text from PDF files and organize it as the input for NLP, either in tables or in words and lines.
- Loyalty points capture
- Automate loyalty points calculations from receipts, based on the number of items or the total amount paid.
Supported Formats
Vision supports several document formats.
- JPEG
- PNG
- TIFF
Pretrained Models
Vision has five types of pretrained model.
Optical Character Recognition (OCR)
Vision can detect and recognize text in a document. Language classification identifies the language of a document, then OCR draws bounding boxes around the printed or hand-written text it finds in an image, and digitizes the text.
If you have a PDF with text, Vision finds the text in that document and extracts the text. It then provides bounding boxes for the identified text. Text Detection can be used with Document AI or Image Analysis models.
Vision provides a confidence score for each text grouping. The confidence score is a decimal number. Scores closer to 1 indicate a higher confidence in the extracted text, while lower scores indicate lower confidence score. The range of the confidence score for each label is from 0 to 1.
OCR support is limited to English. If you know that the text in the images is in English, set the language to
Eng.- Word extraction
- Text line extraction
- Confidence score
- Bounding polygons
- Single request
- Batch request
- Although Language classification identifies several languages, OCR is limited to English.
An example of OCR use in Vision.
- Input document
-
OCR Input

.{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "TEXT_DETECTION" }, { "featureType": "LANGUAGE_CLASSIFICATION", "maxResults": 5 } ] } } - Output:
- OCR Output
 API Response:
API Response: { "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 }, { "languageCode": "ARA", "confidence": 4.7619238e-7 }, { "languageCode": "NLD", "confidence": 7.2325456e-8 }, { "languageCode": "CHI_SIM", "confidence": 3.0645523e-8 }, { "languageCode": "ITA", "confidence": 8.6900076e-10 } ], "words": [ { "text": "Example", "confidence": 0.99908227, "boundingPolygon": { "normalizedVertices": [ { "x": 0.0664819944598338, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.035 }, { "x": 0.0664819944598338, "y": 0.035 } ] } ... "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 } ], ...
Document Classification
Document Classification can be used to classify a document.
- Invoice
- Receipt
- Resume or CV
- Tax form
- Driver's license
- Passport
- Bank statement
- Check
- Payslip
- Other
- Classify document
- Confidence score
- Single request
- Batch request
An example of document classification use in Vision.
- Input document
- Document Classification Input
- Output:
- API Response:
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 }, { "documentType": "TAX_FORM", "confidence": 6.465067e-9 }, { "documentType": "CHECK", "confidence": 6.031838e-9 }, { "documentType": "BANK_STATEMENT", "confidence": 5.413888e-9 }, { "documentType": "PASSPORT", "confidence": 1.5554872e-9 } ], ... detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 } ], ...
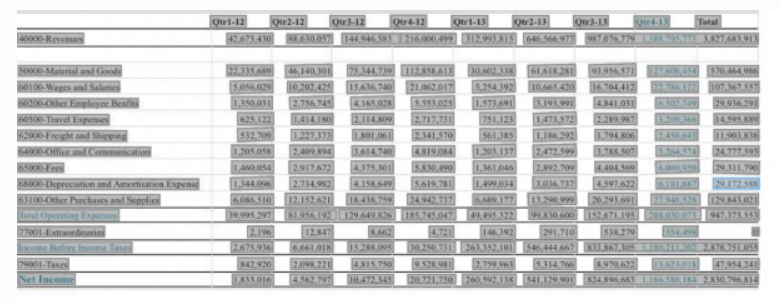
Table Extraction
Table extraction can be used to identify tables in a document and extract their contents. For example, if a PDF receipt contains a table that includes the taxes and total amount, Vision identifies the table and extract the table structure.
Vision provides the number of rows and columns for the table and the contents in each table cell. Each cell has a confidence score. The confidence score is a decimal number. Scores closer to 1 indicate a higher confidence in the extracted text, while lower scores indicate lower confidence score. The range of the confidence score for each label is from 0 to 1.
- Table extraction for tables with and without borders
- Bounding polygons
- Confidence score
- Single request
- Batch request
- English language only
An example of table extraction use in Vision.
- Input document
- Table Extraction Input
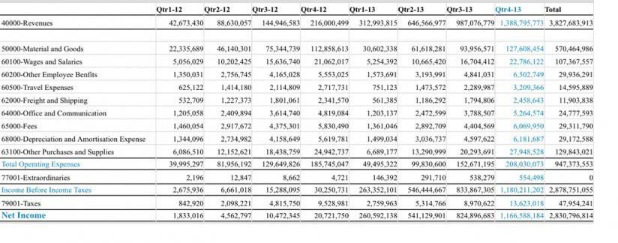
- Output:
- Table Extraction Output
Key Value Extraction (Receipts)
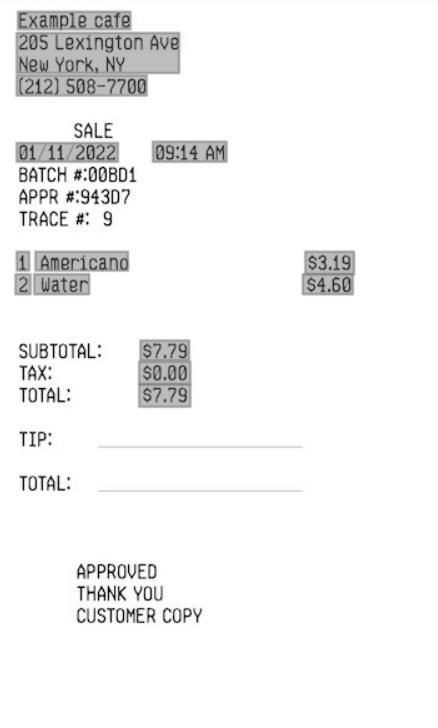
Key value extraction can be used to identify values for predefined keys in a receipt. For example, if a receipt includes a merchant name, merchant address, or merchant phone number, Vision can identify these values and return them as a key value pair.
- Extract values for predefined key value pairs
- Bounding polygons
- Single request
- Batch request
- Supports receipts in English only.
- MerchantName
- The name of the merchant issuing the receipt.
- MerchantPhoneNumber
- The telephone number of the merchant.
- MerchantAddress
- The address of the merchant.
- TransactionDate
- The date the receipt was issued.
- TransactionTime
- The time the receipt was issued.
- Total
- The total amount of the receipt, after all charges and taxes have been applied.
- Subtotal
- The subtotal before taxes.
- Tax
- Any sales taxes.
- Tip
- The amount of tip given by the purchaser.
- ItemName
- Name of the item.
- ItemPrice
- Unit price of the item.
- ItemQuantity
- The number of each items bought.
- ItemTotalPrice
- The total price of the line item.
An example of key value extraction use in Vision.
- Input document
- Key Value Extraction (Receipts) Input
- Output:
- Key Value Extraction (Receipts) Output
Optical Character Recognition (OCR) PDF
OCR PDF generates a searchable PDF file in your Object Storage. For example, Vision can take a PDF file with text and images, and return a PDF file where you can search for the text in the PDF.
- Generate searchable PDF
- Single request
- Batch request
An example of OCR PDF use in Vision.
- Input
-
OCR ODF Input
 API Request:
API Request:{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "source": "INLINE", "data": "......" }, "features": [ { "featureType": "TEXT_DETECTION", "generateSearchablePdf": true } ] } } - Output:
- Searchable PDF.
Using the Pretrained Document AI Models
Vision provides pretrained models for customers to extract insights about their documents without needing Data Scientists.
You need the following before using a pretrained model:
-
A paid tenancy account in Oracle Cloud Infrastructure.
-
Familiarity with Oracle Cloud Infrastructure Object Storage.
You can call the pretrained Document AI models as a batch request using Rest APIs, SDK, or CLI. You can call the pretrained Document AI models as a single request using the Console, Rest APIs, SDK, or CLI.
See the Limits section for information on what is allowed in batch requests.